
Long-term memory for LangChain agents
Three LangChain agents — an intake nurse, a doctor, and a pharmacist — share one patient's memory through xysq. Same patient, three separate processes, one memory layer that survives restarts.

Most agent frameworks only remember the current runtime. When the process exits, the conversation resets, the scratchpad disappears, and the next agent starts from zero.
That's fine for a chatbot. It is not fine for anything that needs to continue — a tutoring session resumed next week, a sales account picked up by a different rep, a patient seen across an intake, a diagnosis, and a pharmacy pickup.
This post walks through a minimal demo that makes the problem concrete: three LangChain agents — an intake nurse, a doctor, and a pharmacist — handing a patient off through nothing but memory. Same model, same graph, three different personas. No shared database, no API between them, no orchestrator. Just a memory layer the framework doesn't own.
What dies when the process dies#
xysq separates memory from the framework itself. The runtime can die. The memory persists.
| Without xysq | With xysq |
|---|---|
| Each agent starts from zero | Every agent picks up where the last left off |
| Memory dies when the process exits | Memory persists across sessions and frameworks |
| Patient repeats themselves every visit | Patient's history follows them automatically |
Two tools is the whole integration#
Two tools. Every agent gets the same two.
import os
from dotenv import load_dotenv
from langchain_core.tools import tool
from xysq import AsyncXysq
load_dotenv()
client = AsyncXysq(api_key=os.environ["XYSQ_API_KEY"])
@tool
async def recall_memory(query: str) -> str:
"""Recall information from the patient's persistent memory."""
items = await client.memory.surface(query=query, budget="mid", domain="health")
if not items:
return "No relevant memory found."
return "Recalled from memory:\n" + "\n".join(f"- {item.text}" for item in items[:5])
@tool
async def store_memory(content: str) -> str:
"""Store an important fact in the patient's persistent memory."""
await client.memory.capture(content=content, significance="high")
return f"Stored: {content[:60]}..."No migrations. No vector pipeline. The agent decides what to store and when to recall; the SDK handles the rest.
Watch the patient walk through three rooms#
The demo runs each agent as its own process. Memory is the only handoff.
python demo.py --intake # Patient describes symptoms; agent stores them
python demo.py --doctor # Doctor recalls symptoms; diagnoses; stores Rx
python demo.py --pharm # Pharmacist recalls Rx; counsels patientSession 1 — Intake#
The patient describes their symptoms. Every fact is captured as it's mentioned, persisted immediately, ready for the next agent.
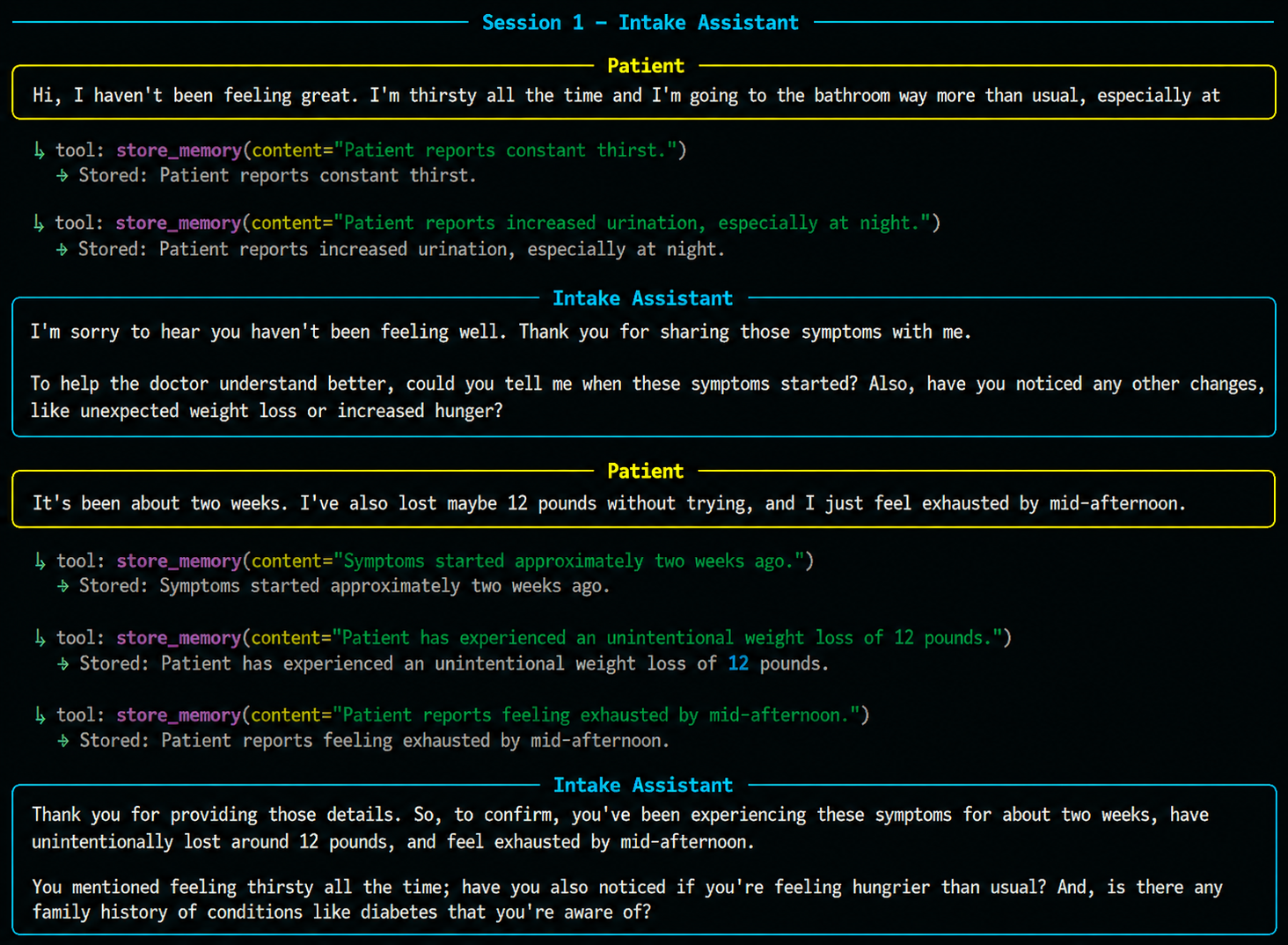
The process exits. The conversation is gone. The memory is not.
Session 2 — Doctor recall#
A new process starts. A different agent. It has never seen the intake conversation.
Its first action: recall_memory("patient's symptoms, history, prior notes").
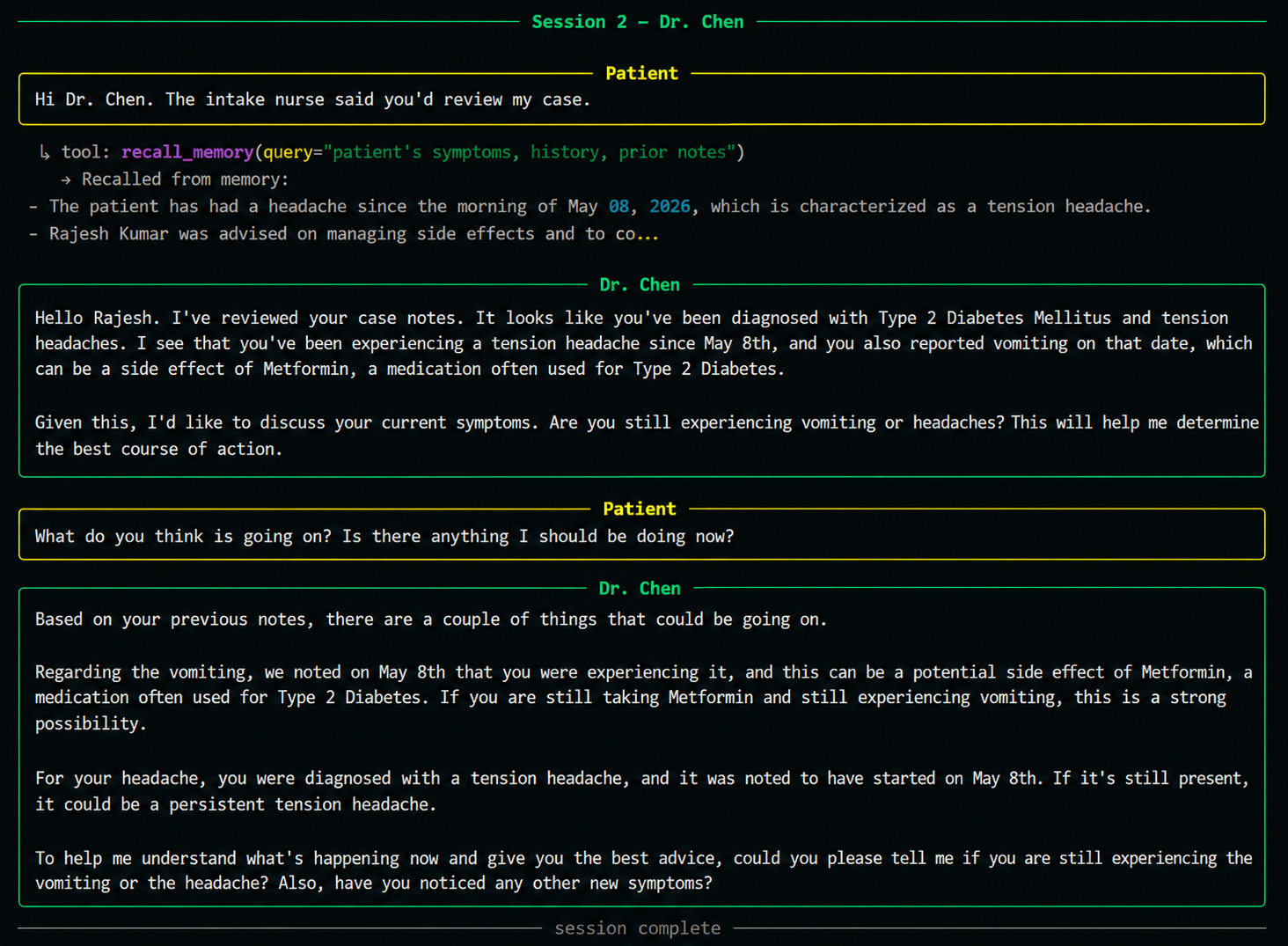
The diagnosis is grounded in recalled memory — not in conversation history, because there isn't one yet. This is the handoff. No API calls between agents, no shared database, no glue code. Just memory.
Session 3 — Pharmacist#
Another new process. The pharmacist has never seen the doctor's visit either.
It recalls the prescription, the diagnosis, and the patient's allergy — all captured across two earlier sessions — and counsels accordingly.
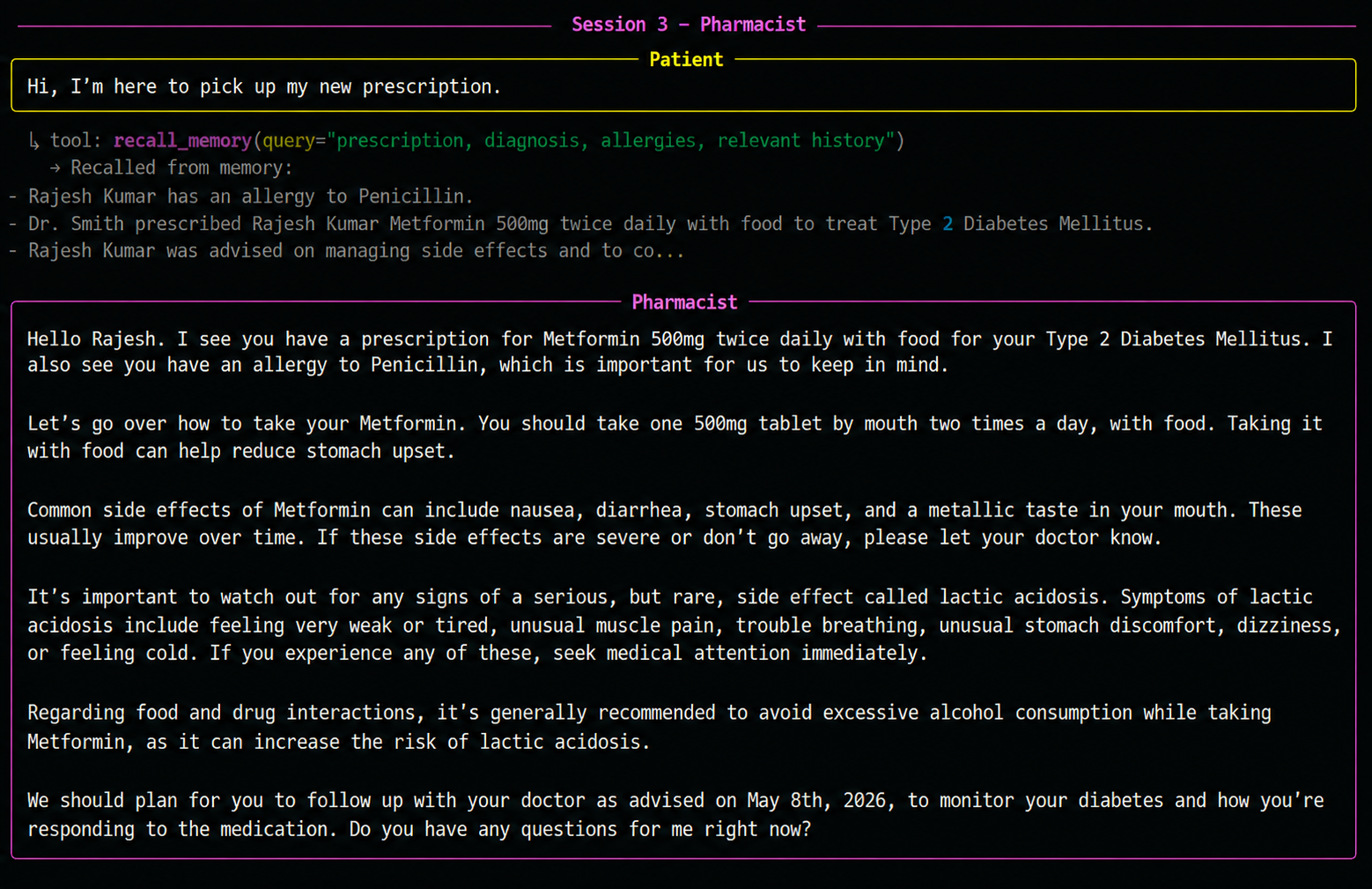
Three agents. Three separate processes. One continuous patient experience.
The patient owns this, not the agent#
Every stored fact appears immediately in the xysq dashboard — searchable, editable, deletable by the user. The agent doesn't own this data. The user does.
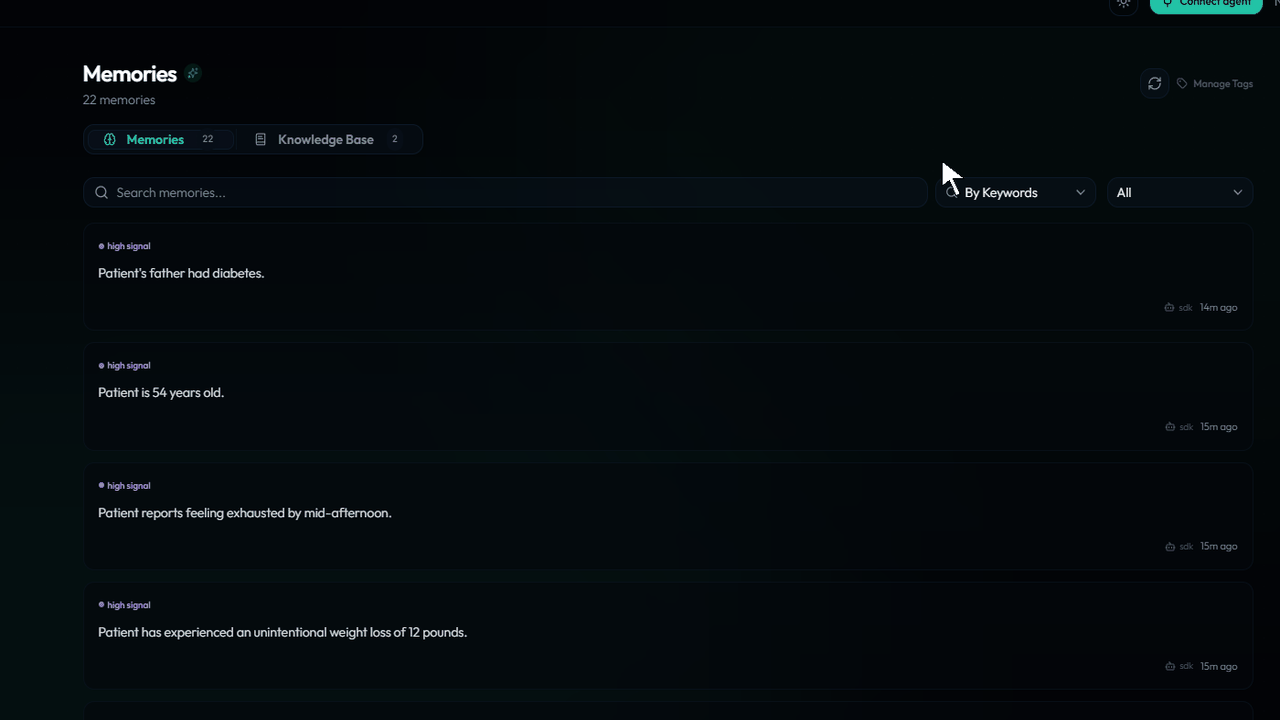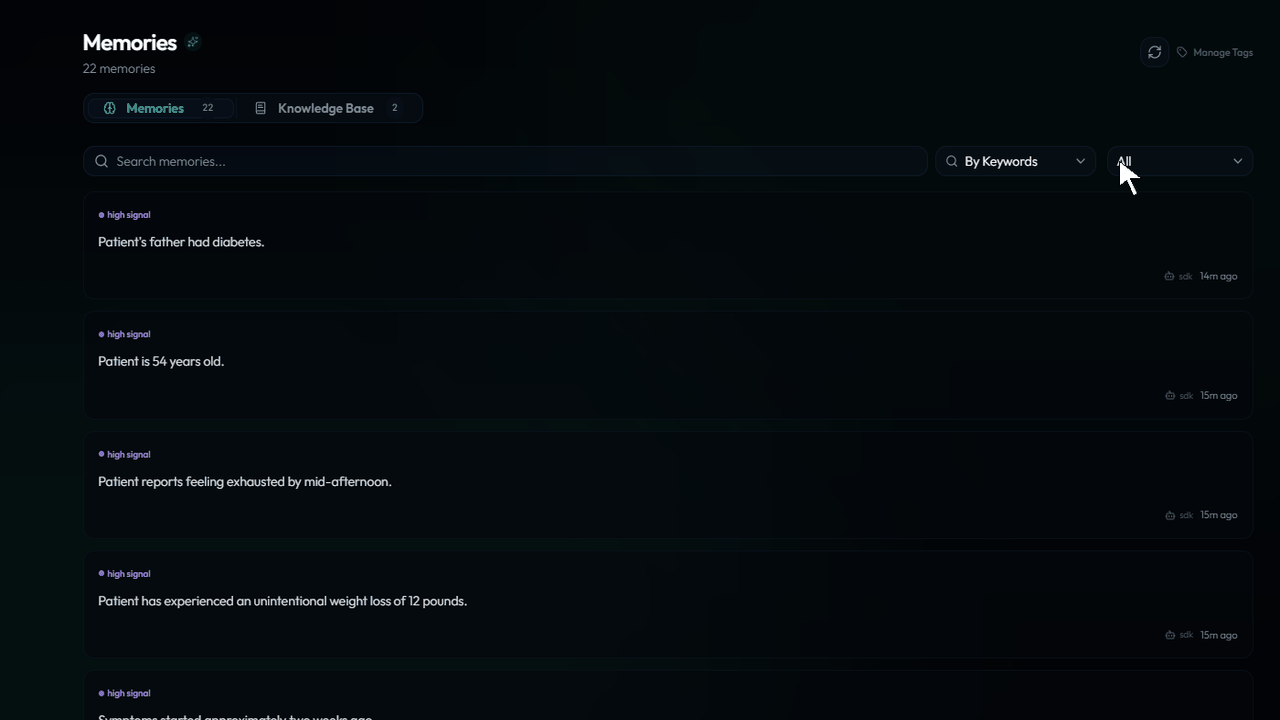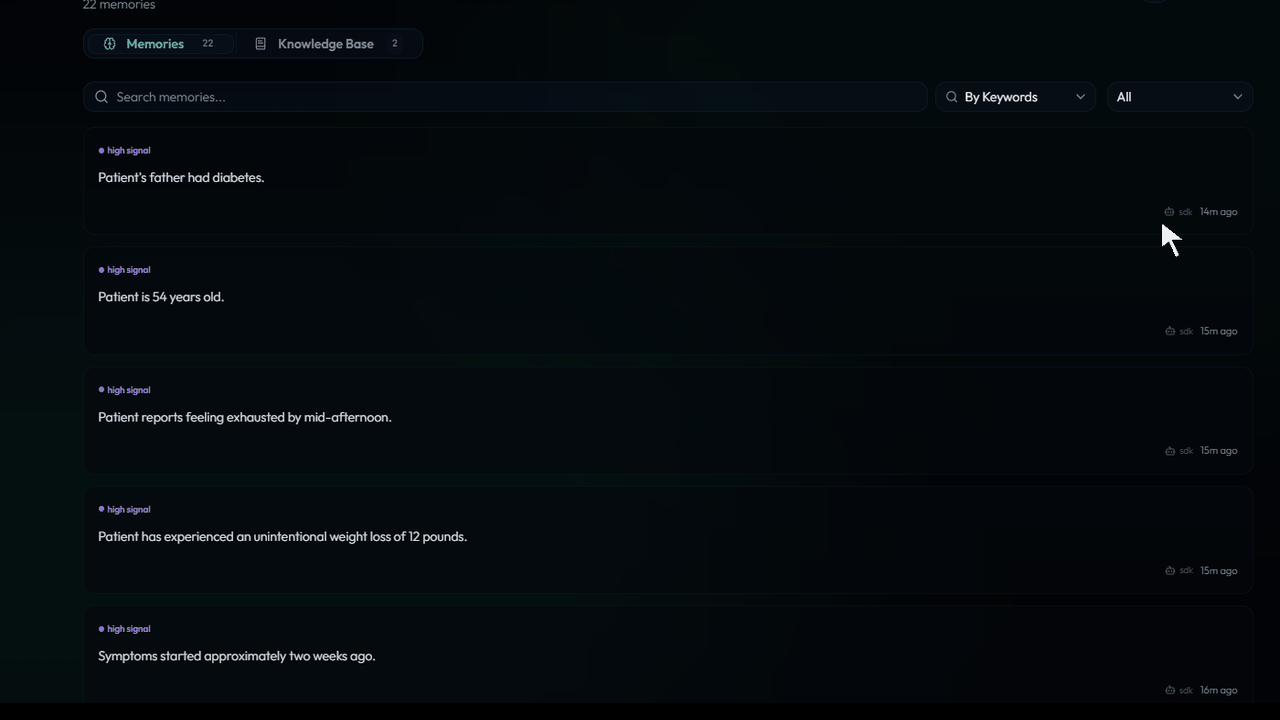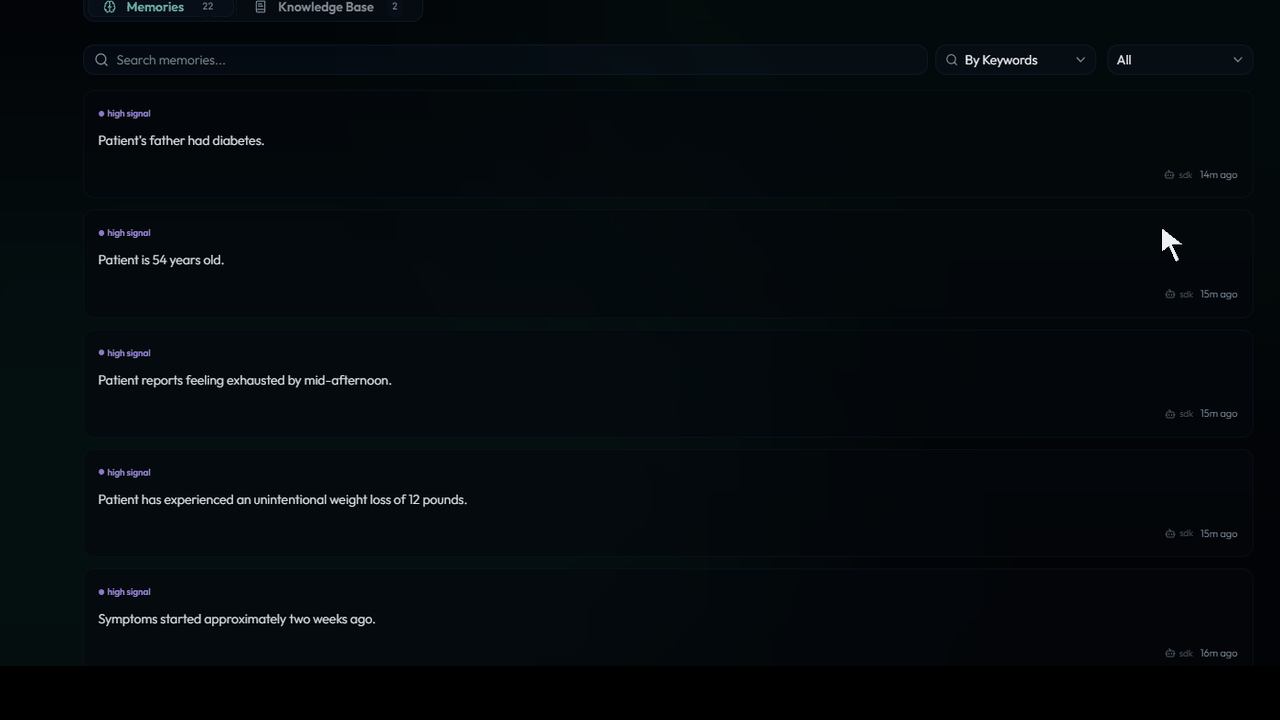
The same memories are accessible to other agents — including Claude via MCP — with user consent. Memory that outlives the framework you happened to use today.
The twist — all three agents are the same code#
def build_agent(persona: str):
system_prompt = (PROMPTS_DIR / f"{persona}.txt").read_text()
llm = ChatGoogleGenerativeAI(model="gemini-2.5-flash", temperature=0.2)
return create_react_agent(
model=llm,
tools=[recall_memory, store_memory],
state_modifier=system_prompt,
)Same model. Same tools. Same graph. Persona changes by swapping the prompt file. The agent identity is just a string. Adding a fourth agent — say a follow-up nurse — is one new prompt file, zero code changes.
Tutors, sales reps, support — same pattern#
The same pattern works anywhere agents need shared, durable context:
- Tutoring agents that remember which topics a student struggled with last week, so today's session picks up where the last one stopped
- Sales agents that remember an account's objections, deal stage, and key contacts — so the next rep doesn't re-ask discovery questions
- Support agents that remember a user's ticket history and previous fixes — so the next agent doesn't make the user repeat themselves
If your product has agents that should feel like one continuous experience to the user — but live in separate runtimes, separate frameworks, or separate sessions — externalising memory is the cheapest way to get there. Two tools, twenty lines, no infrastructure.
The full guide and runnable code are on GitHub.